
(a) Approach

(b) Pregrasp

(c) Lift
UC San Diego, ECE 228: Machine Learning for Physical Applications · Spring Quarter 2026
Code | Report | ViViDex Paper
ViViDex (ICRA 2025) learns vision-based dexterous manipulation from a single human video demonstration. It extracts a reference trajectory from multi-view RGB-D data, trains a state-based policy via trajectory-guided PPO in MuJoCo, then distills it into a vision-based policy via Behaviour Cloning on rendered rollouts.
This project reproduces the first two stages of the pipeline from scratch: reference trajectory extraction from DexYCB and trajectory-guided PPO training on the MuJoCo Adroit hand. ViViDex does not release its retargeting code, so we derive the full camera-to-world coordinate transform from DexYCB calibration data and implement two retargeting variants to study the effect of retargeting quality on downstream training.
DexYCB captures human hand-object interactions from 8 synchronized RGB-D cameras. Human annotators label 2D joint keypoints per view; DexYCB fits the MANO hand model jointly across all 8 views to recover accurate 3D hand trajectories. Each frame stores 21 hand joint positions in camera space, along with object pose as a rotation-translation matrix.
(a) Approach
(b) Pregrasp
(c) Lift
We reconstruct the 3D MANO hand mesh per frame using subject-specific shape parameters β and per-frame pose parameters θ, then transform all poses from camera space to the simulator world frame via the derived coordinate transform. Object translation and orientation match ViViDex's reference NPZ exactly.

(a) MANO approach

(b) MANO pregrasp

(c) MANO lift
Because MANO and Adroit differ in kinematic structure, we solve a per-frame NLopt optimization matching 6 target body positions (palm + 5 middle phalanges) on the Adroit hand to corresponding human joint positions in world space, with temporal smoothness regularization. We implement two variants:

(a) Baseline init

(b) Baseline pregrasp

(c) Baseline manip
ViViDex reference trajectory (undisclosed pipeline)

(d) Naive init

(e) Naive pregrasp -- insufficient abduction

(f) Naive manip
Naive retargeting (position-only NLopt)

(g) Chain init

(h) Chain pregrasp -- improved spread

(i) Chain manip
Chain retargeting (MANO global frame initialization)
Each retargeted trajectory is used as a reference for trajectory-guided PPO in MuJoCo (Adroit hand, mustard bottle relocate task). The two-phase reward guides the policy through pregrasp hand matching followed by object trajectory tracking with a lift bonus. All runs used 32 parallel environments, approximately 200k gradient updates, and approximately 1.5x108 total environment steps on Google Colab (12 CPU cores, NVIDIA L4). MuJoCo is CPU-bound; GPU utilization remained below 1% throughout.
The baseline training curve reveals a sharp phase transition around 80-90M total steps (shown as approximately 40-50M on the per-session x-axis due to Colab session resets), where hand success jumps from 0.68 to 0.85 and object success rises from 0.55 to 0.80. Goal success first appears only after this transition.
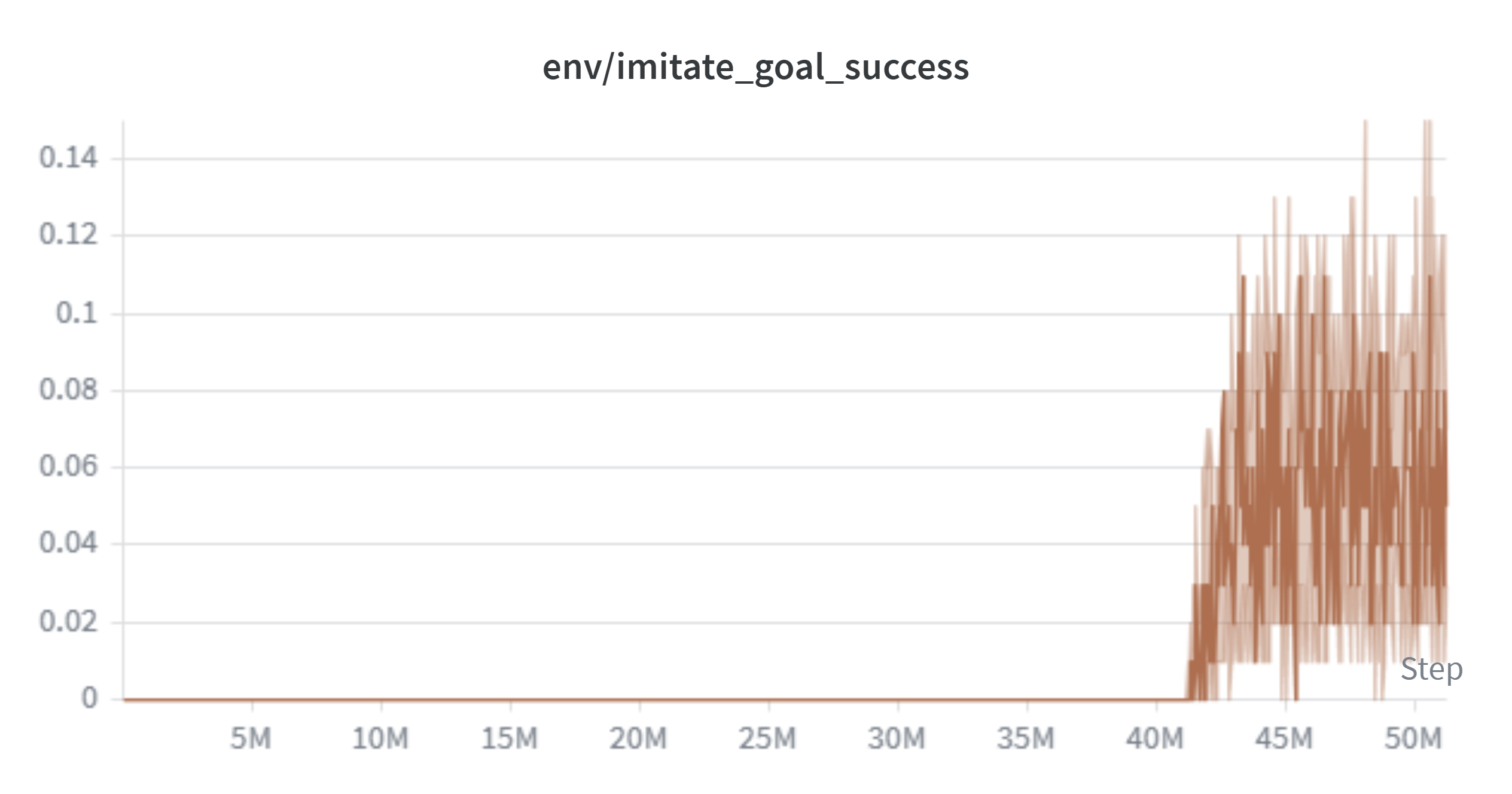
Goal success
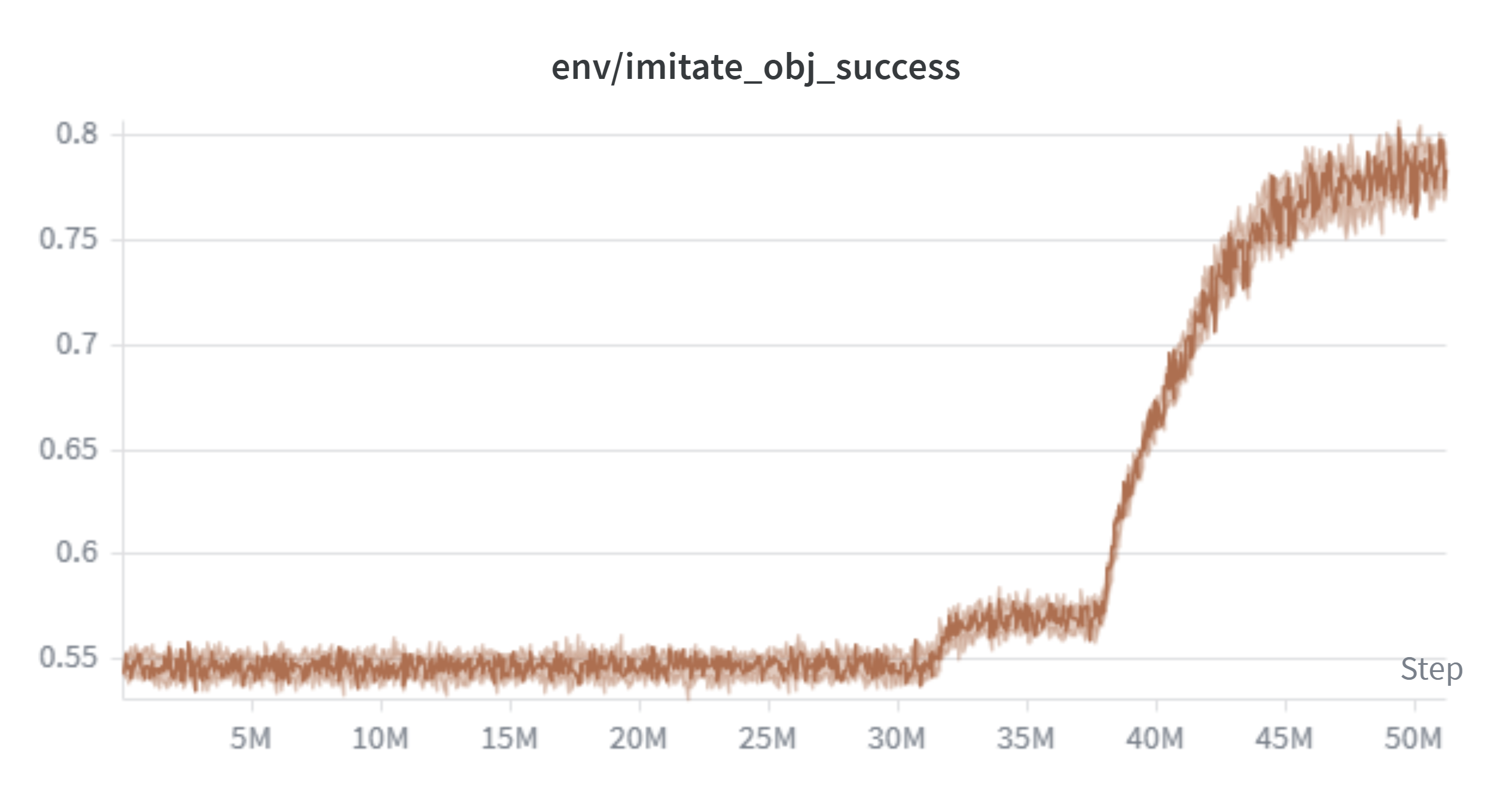
Object success
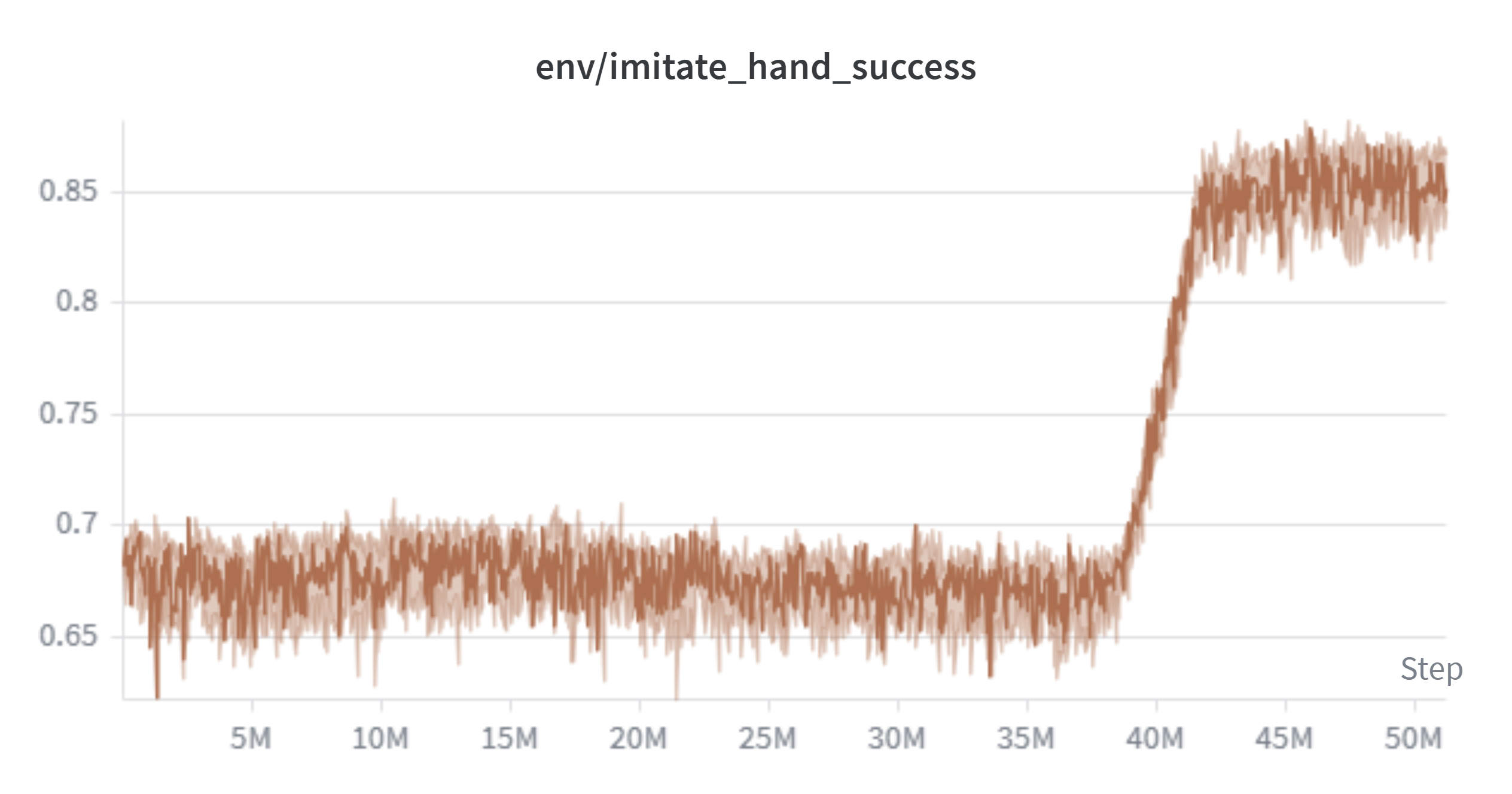
Hand success
| Method | Goal Success | Object Success | Hand Success | Grad. Updates |
|---|---|---|---|---|
| Baseline (ViViDex ref.) | 0.190 | 0.812 | 0.887 | 197,745 |
| Chain (ours) | 0.000 | 0.547 | 0.841 | 198,695 |
| Naive (ours) | 0.000 | 0.519 | 0.180 | 222,145 |

(a) Pretrained init

(b) Pretrained pregrasp

(c) Pretrained -- successful lift
ViViDex pretrained checkpoint

(d) Baseline init

(e) Baseline pregrasp

(f) Baseline -- partial lift
Our baseline policy (ViViDex reference trajectory, trained from scratch)

(g) Chain init

(h) Chain pregrasp

(i) Chain -- contact but no lift
Chain retargeting policy

(j) Naive init

(k) Naive pregrasp

(l) Naive -- fails to grasp
Naive retargeting policy
The green marker is the target object position; the dark circle marks the initial position on the table.